08. Суперконвейерные, суперскалярные процессоры.
Гиперпотоковая технология
Суперконвейерные
процессоры
Эффективность
конвейера находится в прямой зависимости от того, с какой частотой на его вход
подаются объекты обработки. Добиться n-кратного увеличения темпа работы конвейера можно двумя путями:
■
разбиением каждой ступени конвейера на п «подступеней» при одновременном
повышении тактовой частоты внутри конвейера также в п раз;
■
включением в состав процессора п конвейеров, работающих с перекрытием.
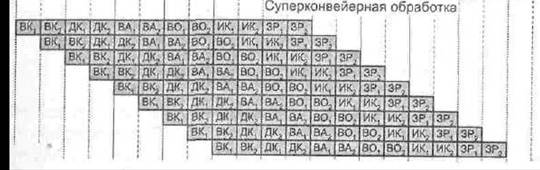
Каждая из
ступеней стандартного конвейера разбита па две более простые подступени,
обозначенные индексами 1 и 2. Выполнение операции в подступенях занимает
половину тактового периода. Тактирование операций внутри конвейера производится
с частотой, вдвое превышающей частоту «внешнего» тактирования конвейера,
благодаря чему на каждой ступени конвейера можно в пределах одного «внешнего»
тактового периода выполнить две команды.

В сущности,
суперконвейеризация сводится к увеличению количества ступеней конвейера, как за
счет добавления новых ступеней, так и путем дробления имеющихся
ступеней на несколько простых подступеней. Главное требование — возможность
реализации операции в каждой подступени наиболее простыми техническими
средствами, а значит, с минимальными затратами времени. Вторым, не менее
важным, условием является одинаковость задержки во всех подступенях.
Критерием
для причисления процессора к суперконвейерным служит число ступеней в конвейере
команд. К суперконвейерным относят процессоры, где таких ступеней больше шести.
Рис. 9.36. Традиционная и суперконвейерная
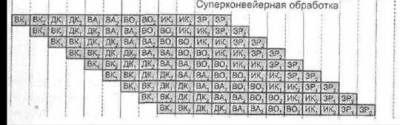
Суперконвейеризация
здесь стала следствием разбиения этапов выборки команды и выборки операнда, а
также введения в конвейер дополнительного этапа проверки тега, появление
которой обусловлено архитектурой системы команд машины.
Удлинение
конвейера ведет не только к усугублению проблем, характерных для любого
конвейера, но и возникновению дополнительных сложностей. В длинном конвейере
возрастает вероятность конфликтов. Дороже встает ошибка предсказания перехода —
приходится очищать большее число ступеней конвейера, на что требуется больше
времени. Усложняется логика взаимодействия ступеней конвейера.
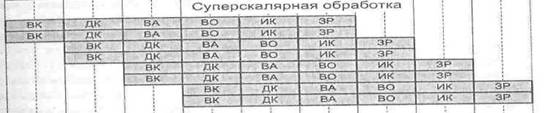
Суперскалярные процессоры. Суперскалярным называется центральный процессор (ЦП),
который одновременно выполняет более чем одну скалярную команду. Это
достигается за счет включения в состав ЦП нескольких самостоятельных
функциональных (исполнительных) блоков, каждый из которых отвечает за свой
класс операций и может присутствовать в процессоре в нескольких экземплярах.
Так, в микропроцессоре Pentium
III блоки целочисленной арифметики и операций
с плавающей точкой дублированы, а в микропроцессорах Pentium 4 и Athlon — троированы. Структура типичного
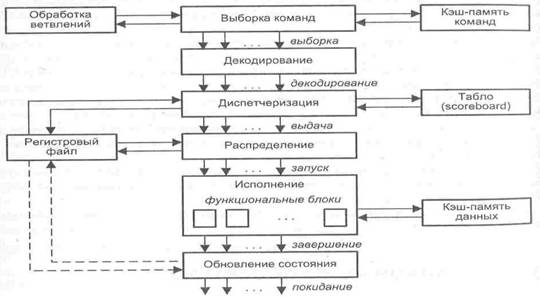
суперскалярного процессора показана на рис. 9.40. Процессор включает в себя
шесть блоков: выборки команд, декодирования команд, диспетчеризации команд,
распределения команд пф функциональным
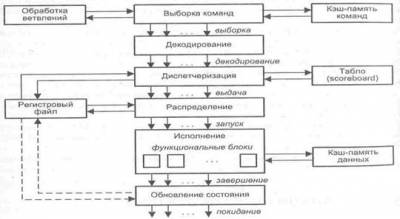
блокам, блок
исполнения и блок обновления состояния.
Блок
выборки команд извлекает
команды из основной памяти через кэш-память команд. Этот блок хранит несколько
значений счетчика команд и обрабатывает команды условного перехода.
Блок
декодирования расшифровывает
код операции, содержащийся в извлеченных из кэш-памяти командах. В некоторых
суперскалярных, процессорах, например в микропроцессорах фирмы Intel, блоки выборки и декодирования совмещены.
Блоки диспетчеризации и
распределения взаимодействуют
между собой и в совокупности играют в суперскалярном процессоре роль
контроллера трафика. Оба блока хранят очереди декодированных команд. Очередь
блока распределения часто рассредоточивается по несколько самостоятельным
буферам — накопителям команд или схемам резервирования (reservation station),- предназначенным для хранения команд, которые уже декодированы,
но еще не выполнены. Каждый накопитель команд связан со своим функциональным
блоком (ФБ), поэтому число накопителей обычно равно числу ФБ, но если в
процессоре используется несколько однотипных ФБ, то им придается общий
накопитель. По отношению к блоку диспетчеризации накопители команд выступают в
роли виртуальных функциональных устройств.
В
дополнение к очереди, блок диспетчеризации хранит также список свободных
функциональных блоков, называемый табло (Scoreboard). Табло используется для отслеживания состояния очереди распределения.
Один раз за цикл блок диспетчеризации извлекает команды из своей очереди,
считывает из памяти или регистров операнды этих команд, после чего, в
зависимости от состояния табло, помещает команды и значения операндов в очередь
распределения. Эта операция называется выдачей команд. Блок
распределения в каждом цикле проверяет каждую команду в своих очередях на
наличие всех необходимых для ее выполнения операндов и при положительном ответе
начинает выполнение таких команд в соответствующем функциональном блоке.
Блок
исполнения состоит из
набора функциональных блоков. Примерами ФБ могут служить целочисленные
операционные блоки, блоки умножения и сложения с плавающей запятой, блок
доступа к памяти. Когда исполнение команды завершается, ее результат
записывается и анализируется блоком обновления состояния, который обеспечивает учет
полученного результата теми командами в очередях распределения, где этот
результат выступает в качестве одного из операндов.
Как было
отмечено ранее, суперскалярность предполагает параллельную работу максимального
числа исполнительных блоков, что возможно лишь при односменном выполнении
нескольких скалярных команд. Последнее условие хорошо сочетается с конвейерной
обработкой, при этом желательно, чтобы в суперскалярном процессоре было
несколько конвейеров, например два или три.
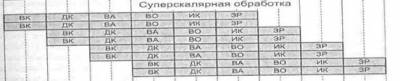

В
процессорах некоторых ВМ реализованы как суперскалярность, так и
суперконвейеризация. Такое совмещение имеет место в микропроцессора Athlon и Duron фирмы AMD, причем охватывает оно не только конвейер команд, но и блок обработки чисел в форме с плавающей
запятой.
В процессорах Pentium
4 (начиная с частоты 3,06 ГГц) применяется гиперпотоковая
(hyperthreading) технология: один физический процессор одновременно может
выполнять два потока инструкций х86. Для фон-неймановской машины это означает,
что физический процессор имеет два комплекта архитектурных (прикладных и
системных) регистров. В каждом комплекте имеется, естественно, свой указатель
инструкций, «идущий» по своему потоку. Таким образом, речь идет о двух
логических процессорах, физически расположенных на одном кристалле микросхемы.
Эти логические процессоры совместно используют ряд общих микроархитектурных
блоков физического процессора (вторичный кэш, исполнительные блоки
арифметико-логического устройства). Такое разделение позволяет повысить
эффективность функционирования исполнительных блоков.
Производительность
систем с Hyper-Threading, как правило, значительно превышает аналогичные параметры
компьютеров, построенных на основе процессоров традиционной архитектуры.
•
высокоскоростная шина обмена
данных между устройствами 2) масштабируемая архитектура, упрощая возможность
соединения устройств; 3) совместима с существующими шинами передачи данных,
существующими и проектируемыми операционными системами 4) обладает возможностью
взаимодействия с современными шинами ввода/вывода 5) устройства, построенные с
использованием технологии HyperTransportTM, спроектированы для работы на частотах от 200 до 800
МГц и используют технологию передачи данных по обоим фронтам синхросигнала,
передавая по два бита информации за каждый такт с эффективной скоростью в
каждом направлении.
Состав шины HyperTransport:
•
1.Контроллер шины (host);
является источником данных и сигналов для других устройств – мостов, туннелей и
конечных узлов. Обычно встраивается в процессор (в северный мост). 2.Туннель
шины (tunnel); устройство с двумя контактами, входным и
выходным, с функциональным устройством между ними. Туннель является основным
соединительным блоком устройств HyperTransportTM.
Команды, не адресованные туннельному устройству, транслируются через него далее
по цепи. 3.Конечный узел (end device); образует конечную точку
цепи HyperTransportTM4.Концентратор (hub); микросхема
южного моста, управляющая устройствами IDE и менее
скоростными портами, включая последовательные и параллельные порты, USB, IEEE-1394
и т.д. 5.Переключатель (switch); управляет потоками ввода/вывода и организует
внутреннее соединение подключенных к шине HyperTransportTM устройств. Контроллер непосредственно взаимодействует
с переключателем, который обслуживает множество независимых подчиненных
устройств, включая туннельные устройства, мосты и конечные устройства цепи, в
порядке очередности. Для исходящих потоков данных переключатель является
ведущим узлом этой цепи; переключатель может соединяться с несколькими
контроллерами и логически разделять структуру на подмножества, доступные для
различных контроллеров. Переключатель поддерживает "горячее” подключение устройств.
6.Мост (bridge).