02. Архитектуры процессоров и их сравнительная оценка.
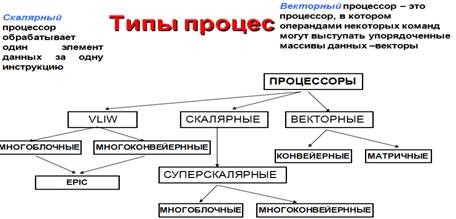
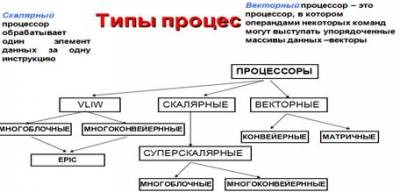
Процессоры CISC, RISC, VLIW, MISC и их особенности
Архитектура фон Неймана
Большинство
современных процессоров для персональных компьютеров в общем основаны на той
или иной версии циклического процесса последовательной обработки данных,
изобретённого Джоном фон Нейманом.
Важнейшие этапы этого процесса:
1) Процессор выставляет число, хранящееся в регистре
счётчика команд, на шину адреса и отдаёт памяти команду чтения.
2) Выставленное число является для памяти адресом;
память, получив адрес и команду чтения, выставляет содержимое, хранящееся по
этому адресу, на шину данных и сообщает о готовности.
3) Процессор получает число с шины данных,
интерпретирует его как команду (машинную инструкцию) из своей системы команд и
исполняет её.
4) Если последняя команда не является командой
перехода, процессор увеличивает на единицу (в предположении, что длина каждой
команды равна единице) число, хранящееся в счётчике команд; в результате там
образуется адрес следующей команды.
В различных архитектурах и для различных команд могут
потребоваться дополнительные этапы. Например, для арифметических команд могут
потребоваться дополнительные обращения к памяти, во время которых производится
считывание операндов и запись результатов. Отличительной особенностью
архитектуры фон Неймана является то, что инструкции и данные хранятся в одной и
той же памяти.
Конвейерная архитектура
Конвейерная архитектура была введена в центральный
процессор с целью повышения быстродействия. Обычно для выполнения каждой
команды требуется осуществить некоторое количество однотипных операций,
например: выборка команды из ОЗУ, дешифровка команды, адресация операнда в ОЗУ,
выборка операнда из ОЗУ, выполнение команды, запись результата в ОЗУ. Каждую из
этих операций сопоставляют одной ступени конвейера. Например, конвейер
микропроцессора с архитектурой MIPS-I содержит четыре стадии:
1) получение и декодирование инструкции, 2) адресация
и выборка операнда из ОЗУ, 3) выполнение арифметических операций, 4) сохранение
результата операции.
После освобождения k-й ступени конвейера она сразу
приступает к работе над следующей командой. Если предположить, что каждая
ступень конвейера тратит единицу времени на свою работу, то выполнение команды
на конвейере длиной в n ступеней займёт n единиц времени, однако в самом
оптимистичном случае результат выполнения каждой следующей команды будет
получаться через каждую единицу времени.
Некоторые современные процессоры имеют более 30
ступеней в конвейере, что увеличивает производительность процессора, однако
приводит к большому времени простоя (например, в случае ошибки в предсказании
условного перехода). Не существует единого мнения по поводу оптимальной длины
конвейера: различные программы могут иметь существенно различные требования.
Суперскалярная архитектура
Способность выполнения нескольких машинных инструкций
за один такт процессора путем увеличения числа исполнительных устройств.
Появление этой технологии привело к существенному увеличению
производительности. В то же время существует определенный предел роста числа
исполнительных устройств, при превышении которого производительность
практические перестает расти, а исполнительные устройства простаивают.
Частичным решением этой проблемы являются, например, технология Hyper
Threading.
CISC-процессоры
Complex Instruction Set Computer — вычисления со
сложным набором команд. Процессорная архитектура, основанная на усложнённом
наборе команд. Типичными представителями CISC являются микропроцессоры
семейства x86 (хотя уже много лет эти процессоры являются CISC только по
внешней системе команд: в начале процесса исполнения сложные команды
разбиваются на более простые микрооперации (МОП'ы), исполняемые RISC-ядром).
RISC-процессоры
Reduced Instruction Set Computer — вычисления с
упрощённым набором команд (в литературе слово «reduced» нередко ошибочно
переводят как «сокращённый»). Архитектура процессоров, построенная на основе
упрощённого набора команд. Характеризуется наличием команд фиксированной длины,
большого количества регистров, операций типа регистр-регистр, а также
отсутствием косвенной адресации. Концепция RISC разработана Джоном Коком (John
Cocke) из IBM Research, название придумано Дэвидом Паттерсоном (David
Patterson).
Упрощение набора команд призвано сократить конвейер,
что позволяет избежать задержек на операциях условных и безусловных переходов.
Однородный набор регистров упрощает работу компилятора при оптимизации
исполняемого программного кода. Кроме того, RISC-процессоры отличаются меньшим
энергопотреблением и тепловыделением.
MISC-процессоры
Minimum Instruction Set Computer — вычисления с
минимальным набором команд. Дальнейшее развитие идей команды Чака Мура, который
полагает, что принцип простоты, изначальный для RISC-процессоров, слишком
быстро отошёл на задний план. В пылу борьбы за максимальное быстродействие,
RISC догнал и перегнал многие CISC процессоры по сложности. Архитектура MISC
строится на стековой вычислительной модели с ограниченным числом команд
(примерно 20-30 команд).
VLIW-процессоры
Very Long Instruction Word — очень длинное командное
слово. Архитектура процессоров с явно выраженным параллелизмом вычислений,
заложенным в систему команд процессора. Являются основой для архитектуры EPIC.
Ключевым отличием от суперскалярных CISC-процессоров является то, что для них
загрузкой исполнительных устройств занимается часть процессора (планировщик),
на что отводится достаточно малое время, в то время как загрузкой
вычислительных устройств для VLIW-процессора занимается компилятор, на что
отводится существенно больше времени (качество загрузки и, соответственно,
производительность теоретически должны быть выше).
VLIW (Very
long instruction word – «очень длинное командное слово») – архитектура
процессоров с несколькими вычислительными модулями. Характеризуется тем, что
одна инструкция процессора содержит несколько операций, которые должны
выполняться параллельно. В суперскалярных процессорах также есть
несколько вычислительных модулей, но задача распределения между ними работы
решается аппаратно. Это сильно усложняет дизайн процессора, и может быть
чревато ошибками. В процессорах VLIW задача распределения решается во время компиляции
и в инструкциях явно указано, какое вычислительное устройство должно выполнять
какую команду.
EPIC (Explicitly
Parallel Instruction Computing – «вычисления с явным параллелизмом команд»). Является
усовершенствованным вариантом технологии VLIW. Первым
представителем данной стратегии стал микропроцессор Itanium компании
Intel.
Гарвардская архитектура
Гарвардская архитектура отличается от архитектуры фон
Неймана тем, что программный код и данные хранятся в разной памяти. В такой
архитектуре невозможны многие методы программирования (например, программа не
может во время выполнения менять свой код; невозможно динамически
перераспределять память между программным кодом и данными); зато гарвардская
архитектура позволяет более эффективно выполнять работу в случае ограниченных
ресурсов, поэтому она часто применяется во встраиваемых системах.
Параллельная архитектура
Архитектура фон Неймана обладает тем недостатком, что
она последовательная. Какой бы огромный массив данных ни требовалось
обработать, каждый его байт должен будет пройти через центральный процессор,
даже если над всеми байтами требуется провести одну и ту же операцию. Этот
эффект называется узким горлышком фон Неймана.
Для преодоления этого недостатка предлагались и
предлагаются архитектуры процессоров, которые называются параллельными.
Параллельные процессоры используются в суперкомпьютерах.
Возможными вариантами параллельной архитектуры могут
служить (по классификации Флинна):
SISD — один поток команд, один поток данных;
SIMD — один поток команд, много потоков данных;
MISD — много потоков команд, один поток данных;
MIMD — много потоков команд, много потоков данных.
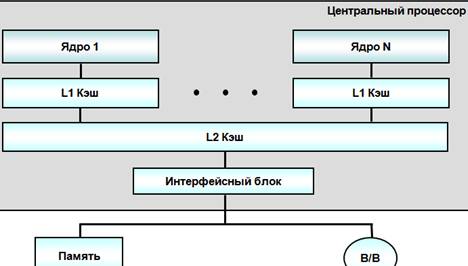
Кэширование
Кэширование — это использование дополнительной
быстродействующей памяти (кеш-памяти) для хранения копий блоков информации из
основной (оперативной) памяти, вероятность обращения к которым в ближайшее
время велика.
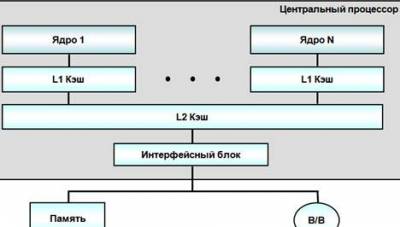
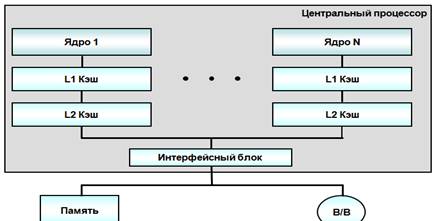
Различают кэши 1-, 2- и 3-го уровней (обозначаются L1,
L2 и L3 — от Level 1, Level 2 и Level 3). Кэш 1-го уровня имеет наименьшую
латентность (время доступа), но малый размер, кроме того, кэши первого уровня
часто делаются многопортовыми. Так, процессоры AMD K8 умели производить
одновременно 64-битные запись и чтение, либо два 64-битных чтения за такт, AMD
K8L может производить два 128-битных чтения или записи в любой комбинации.
Процессоры Intel Core 2 могут производить 128-битные запись и чтение за такт.
Кэш 2-го уровня обычно имеет значительно большую латентность доступа, но его
можно сделать значительно больше по размеру. Кэш 3-го уровня самый большой по
объёму и довольно медленный, но всё же он гораздо быстрее, чем оперативная
память.
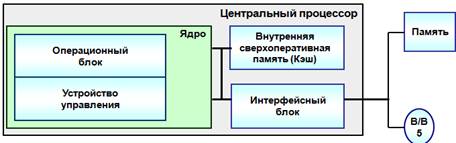
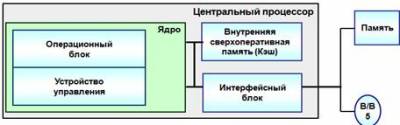
Упрощенная
структура процессора
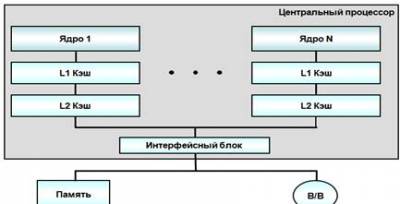
Простая многоядерная
структура процессора
Многоядерная структура с
общей КЭШ